
OpenAI's finance team has publicly described Contract Data Agent / DocuGPT as an operational case study for reducing a recurring bottleneck in contract review. The system reads contract documents in inconsistent formats, including PDFs, scans, mobile phone photos, and handwritten edits, then structures key fields such as billing terms, renewal terms, ASC 606 classification, and non-standard clauses.
The key point is not simple document summarization. The system presents the source pages and clauses behind each extracted value, lets finance reviewers approve or correct the result, and loads the approved data into a warehouse so it can be searched and analyzed later. According to the public case study, review time was cut in half, and thousands of contracts became manageable without scaling headcount linearly.
1. AI techniques used
- Document intake and normalization: Convert PDFs, scans, mobile phone photos, and handwritten edits into a standard text representation through OCR and text extraction.
- Contract metadata generation: Attach contract ID, customer name, amendment status, clause type, and page reference so the contract can be split into searchable units.
- Clause-specific retrieval: Search by clause category, including billing, renewal, termination, discount, non-standard terms, and ASC 606-related sections.
- Structured extraction: Generate field values together with confidence, reasoning, and page citations.
- Human-in-the-loop review: Let finance reviewers approve, correct, or reject extracted values while checking the original citation.
- Warehouse sync: Sync approved fields into finance warehouse and BI systems where they can be queried.
- Eval feedback loop: Reuse reviewer corrections as evaluation data and prompt-improvement input.
2. Implementable system architecture
The structure below is an implementation pattern based on the public case study and a typical enterprise contract-management environment. External integrations such as CLM, e-signature systems, CRM, and S3 can be treated as likely implementation components, but not every integration detail was specified in the original source.
Contract file intake
Contract files arrive in different formats, including PDFs, scans, mobile phone photos, and handwritten edits.
OCR and document normalization
OCR and text extraction convert contract documents into a standard text representation.
Chunking and metadata generation
Searchable units are created by contract ID, customer, clause, and page reference.
Clause retrieval and structured extraction
The system finds clauses related to billing, renewal, ASC 606, and non-standard terms, then generates field values and evidence.
Finance review and warehouse sync
Only values approved by finance reviewers are loaded into contract data that can be queried from the warehouse and BI layer.
If this were built as a production service: AWS reference architecture
The logical flow above can be mapped onto AWS managed services as shown below. Intake, normalization, extraction, review, and loading are mapped to managed components, while the processing and storage layers sit inside a multi-AZ VPC.
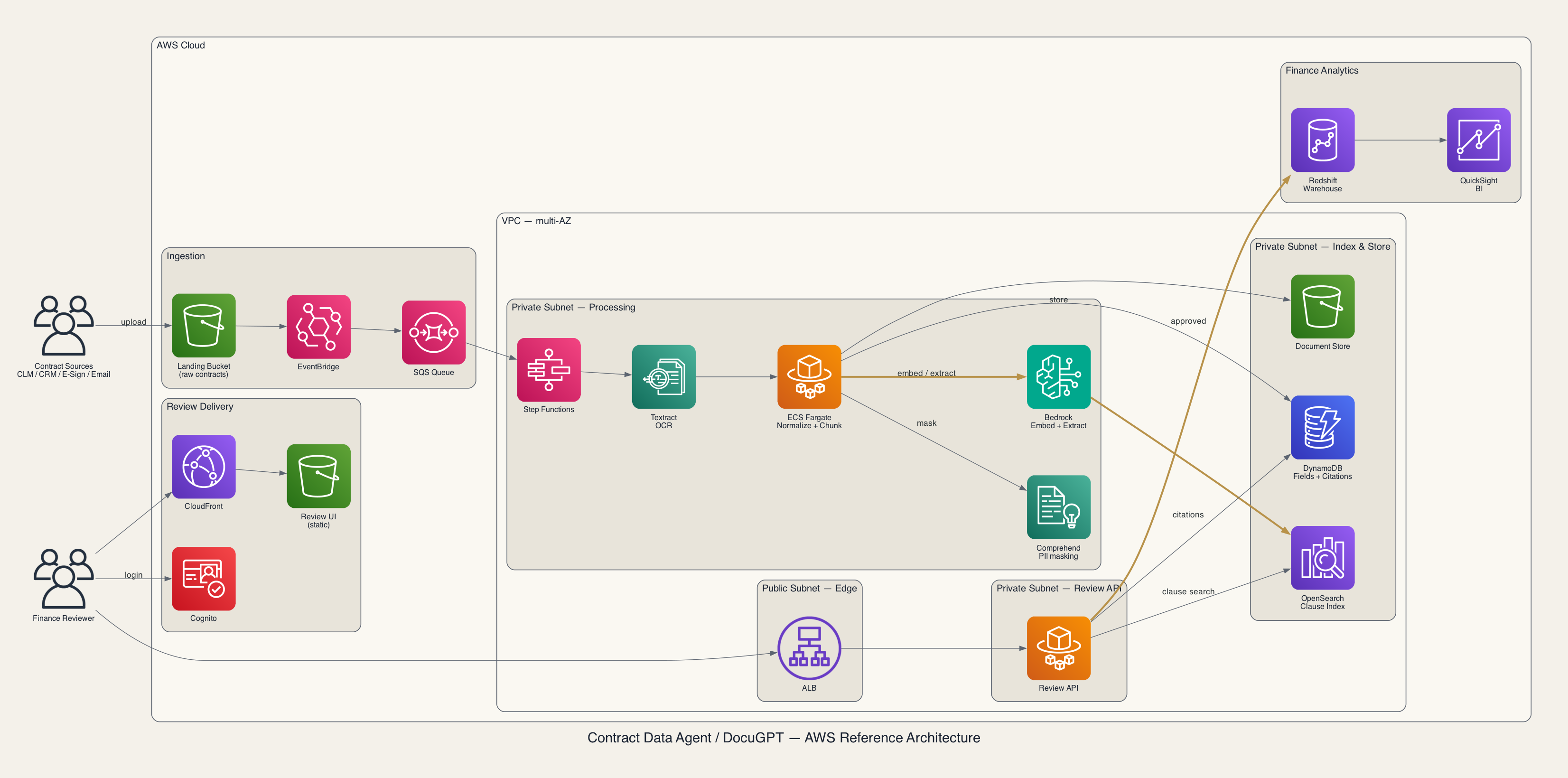
- Contract intake: S3 Landing Bucket, EventBridge, SQS. Store original contracts from external SaaS tools and email attachments, then start the pipeline through events.
- Document normalization: Amazon Textract. Normalize scans, photos, and handwritten edits through OCR.
- Orchestration: AWS Step Functions, ECS Fargate. Control the step-by-step workflow and run normalization and chunking workers.
- Embedding and extraction: Amazon Bedrock. Generate embeddings and extract field values, reasoning, confidence, and citations in a structured format.
- Indexing and retrieval: Amazon OpenSearch Service. Maintain clause-specific search indexes for billing, renewal, ASC 606, and related terms.
- Extracted data: Amazon DynamoDB. Store extracted values, confidence, and page citations.
- Review (human-in-the-loop): CloudFront + S3, public ALB, private ECS Fargate, Amazon Cognito. Provide reviewer UI, API, and authentication.
- Warehouse and BI: Amazon Redshift, Amazon QuickSight. Load approved data and support analytics and dashboards.
- PII masking: Amazon Comprehend. Detect and mask sensitive information such as pricing, customer names, and other contract data.
- Security and audit: IAM, KMS, CloudTrail, CloudWatch. Apply authorization, encryption, audit, and monitoring across the whole path.
The bronze-highlighted path is the core path where cost, latency, and risk concentrate: Bedrock inference and approved-data loading. Security and audit controls apply across the whole system, so they are omitted from the figure and listed above instead. AWS is only one implementation example; the same pattern can be moved to GCP, Azure, or on-premises infrastructure.
Production design details to make explicit
This reference architecture is buildable, but a production design document should make the operating boundaries more explicit.
- Place the Review API in private subnets: CloudFront serves the static review UI, and Cognito handles reviewer authentication. The externally reachable boundary should stop at the public ALB. The ALB applies TLS, WAF, and security-group policy, then forwards traffic only to the ECS Fargate Review API in private subnets. Review API tasks should not receive public IP addresses, and operational access should be limited through SSM Session Manager or the deployment pipeline.
- Let workers validate Bedrock output before writing to OpenSearch: Bedrock does not write directly to OpenSearch. Step Functions runs ECS Fargate workers, and those workers call Bedrock for embedding and extraction, then validate the result against a JSON schema, confidence threshold, and required page citations. Only validated chunks, vectors, and clause metadata should be upserted to OpenSearch. Source documents, extraction results, and review status should remain in S3 and DynamoDB. If Bedrock Knowledge Bases are used, the sync job and approved-data loading path still need separate design.
- Treat PII and language coverage as a policy boundary: Amazon Comprehend PII detection is primarily suited to English and Spanish text, so it may not be enough for Korean contracts or multilingual contract sets. Pricing terms, customer names, account details, addresses, and contact information should be masked with a combination of regex rules, custom NER, Bedrock Guardrails, internal dictionaries, and reviewer checks. OCR quality also depends on scan resolution, handwriting, table structure, and language, so Textract and extraction accuracy should be measured on real contract samples first.
- Design reprocessing, audit, and permission models: Use SQS DLQs, Step Functions retry/catch paths, idempotency keys, and a reviewer-triggered reprocessing action so the same contract is not loaded twice. Every extracted value should keep an audit trail with contract ID, document version, prompt version, model version, source page, reviewer ID, and approval timestamp. IAM should be split into least-privilege roles for ingestion workers, extraction workers, the review API, and the warehouse loader, with KMS key policies, CloudTrail data events, CloudWatch metrics and alarms, and VPC endpoints defined alongside the workload.
3. Operating workflow
Contract intake
Contracts enter the system.
OCR and text normalization
Text is extracted from scans, photos, and PDFs, then normalized into a consistent document shape.
Clause retrieval and AI extraction
Billing, renewal, revenue recognition, and non-standard clauses are found and converted into structured fields.
Reviewer check and approval
Finance reviewers check the citation, then approve or correct the extracted value.
Data loading and improvement loop
Approved data is loaded into the warehouse and BI layer, while correction history feeds back into eval sets and prompt improvements.
In this workflow, AI is not the final decision-maker. It works as an operational support layer that automates contract data extraction and evidence presentation. Important values enter finance systems only after human review and approval.
4. Build and operating cost
OpenAI has not disclosed the internal operating cost. For a similar pilot, the cost structure can be broken down as follows.
- Model API cost: For 1,000 contracts per month, with an average of 30 to 80 pages per contract and 50,000 to 150,000 input tokens per contract after OCR across a two-stage process, monthly model cost can plausibly land in the hundreds to thousands of dollars.
- Document-processing cost: OCR, document storage, embedding indexes, and retrieval infrastructure add separate costs.
- Security and audit cost: Contract and finance data require access control, audit logs, retention policy, and PII or sensitive-data masking.
- Review operating cost: Finance reviewer time can remain a major part of total cost. The benefit is that reviewers spend less time reading every document from scratch and more time judging exceptions and approving critical values.
5. Business value
Shorter contract review time
In the public case study, review time was cut in half. Repetitive searching for values inside contracts decreased, and reviewers could spend more time on exception clauses that require judgment.
Scalability for thousands of contracts
The workflow reduces dependence on adding finance headcount at the same rate as contract volume. This is especially valuable for fast-growing B2B companies.
Searchable contract data
Once approved contract fields are loaded into the warehouse, teams can query billing terms, renewal terms, non-standard terms, and ASC 606 classification. Contracts stop being documents buried in file storage and become finance data that can be analyzed.
Stronger audit readiness
When every extracted value keeps a page citation and reviewer approval trail, it becomes easier to explain why a value was classified a certain way during internal or external audits.
6. Implications for manufacturing and B2B companies
This case extends naturally beyond finance contracts into manufacturing and B2B operating documents. The following document types share similar structure:
- Customer-specific supply contracts and delivery terms
- Warranty terms and penalty clauses
- Equipment maintenance contracts
- Purchase contracts and unit-price change agreements
- Renewal and termination terms in long-term supply agreements
- Import and export documents and Incoterms conditions
The common pattern is that documents are long, formats vary, and the important values are hidden in a small number of clauses. The success requirements are also the same. Instead of letting AI freely summarize every document, teams need to design an operating workflow that connects business field definitions, source evidence, reviewer approval, and warehouse loading.
7. Adoption checklist
- Are the contract fields to extract clearly defined?
- Does each field preserve the source page behind the value?
- Is the finance system untouched until a reviewer approves the value?
- Are reviewer corrections accumulated into an eval set?
- Are contract-document permissions and audit logs maintained?
- Is there a masking policy for sensitive information such as PII, pricing terms, customer names, and payment terms?
- Are warehouse-loaded fields actually used in BI and revenue workflows?
8. References
- Turning contracts into searchable data at OpenAI
- OpenAI API pricing
- OpenAI File Search guide
- OpenAI Function Calling guide