
Carta Healthcare publicly described Lighthouse as an operating case study for reducing the repetitive clinical data abstraction work that hospitals perform when preparing data for more than 70 clinical registries, including NSQIP. Clinical data abstraction is the skilled manual process of reading patient medical records and transferring the right values into registry fields. A single case can take as long as five to six hours. Lighthouse reads both structured EHR data and unstructured clinical notes, then presents a suggested answer and the source medical-record citations behind each registry question.
The core point is not extraction automation by itself. It is a redistribution of roles. Clinical abstractors, a group of more than 200 experts, no longer start by hunting through records for every value. Instead, they validate the answers and citations suggested by AI. AI assists the judgment process rather than replacing it. According to the public case study, processing time fell by up to 66%, while data quality remained at 98-99% IRR, or inter-rater reliability.
1. AI Technologies Used
- FHIR-native data ingestion: FHIR resources such as Patient, Encounter, Observation, DocumentReference, and Procedure are connected from EHR systems so structured data and unstructured clinical notes can be ingested together.
- Runtime context construction: The hardest engineering problem is not a perfect prompt. It is context assembly. For each registry question, patient-specific temporal boundaries, such as pre-procedure measurements relative to procedure start time, are constructed dynamically at runtime.
- Two-stage LLM routing: In Phase 1, Claude Haiku 3.5 and Sonnet 4 broadly extract evidence from medical records. In Phase 2, Claude Sonnet, with Opus 4.5 added from January 2026, synthesizes, scores, and ranks evidence to generate suggested answers.
- Citation-based evidence: Each suggested answer includes direct citations from the source medical record, so abstractors verify rather than search. Temporal reasoning and hallucination-reduction layers operate alongside this flow.
- Human-in-the-loop validation: Every data point is reviewed in the Lighthouse UI by a clinical abstractor before it goes to a registry.
- Fast QA loop: Clinicians can adjust prompts without code changes and test them in production the same day, which shortens the extraction quality improvement cycle.
- PHI-isolated deployment: Claude is called through Amazon Bedrock, and processing stays inside a dedicated AWS account for each customer. The reason is PHI privacy and assurance that customer data is not used for model training.
2. Implementable System Architecture
The structure below is an implementation pattern based on the public case study and a typical clinical data management environment. FHIR integration, dedicated AWS accounts, and registry submission are explicitly described as core design elements in the case, but not every detailed service integration is specified in the original source.
Ingest FHIR data from the EHR
Patient medical records, including structured data and unstructured notes, are ingested from hospital EHR systems through FHIR integration.
Isolate processing in a dedicated AWS account
PHI is processed only inside a dedicated AWS account for each customer, with BAA, SOC 2, and encryption boundaries.
Build context for each registry question
For each question, patient-specific temporal boundaries are assembled at runtime so only the relevant medical-record sections are collected.
Run two-stage extraction and evidence generation
Phase 1 extracts evidence, and Phase 2 synthesizes and scores it to produce suggested answers and citations.
Validate with abstractors and submit to registries
Only values verified by clinical experts and checked against IRR expectations are submitted to clinical registries.
If Built as a Real Service: AWS Reference Architecture
If this logical flow is deployed on AWS, the architecture can look like the pattern below. Intake, context construction, extraction, validation, and submission are mapped to managed services, and the full processing path remains inside the customer-dedicated AWS account, which forms the PHI boundary.
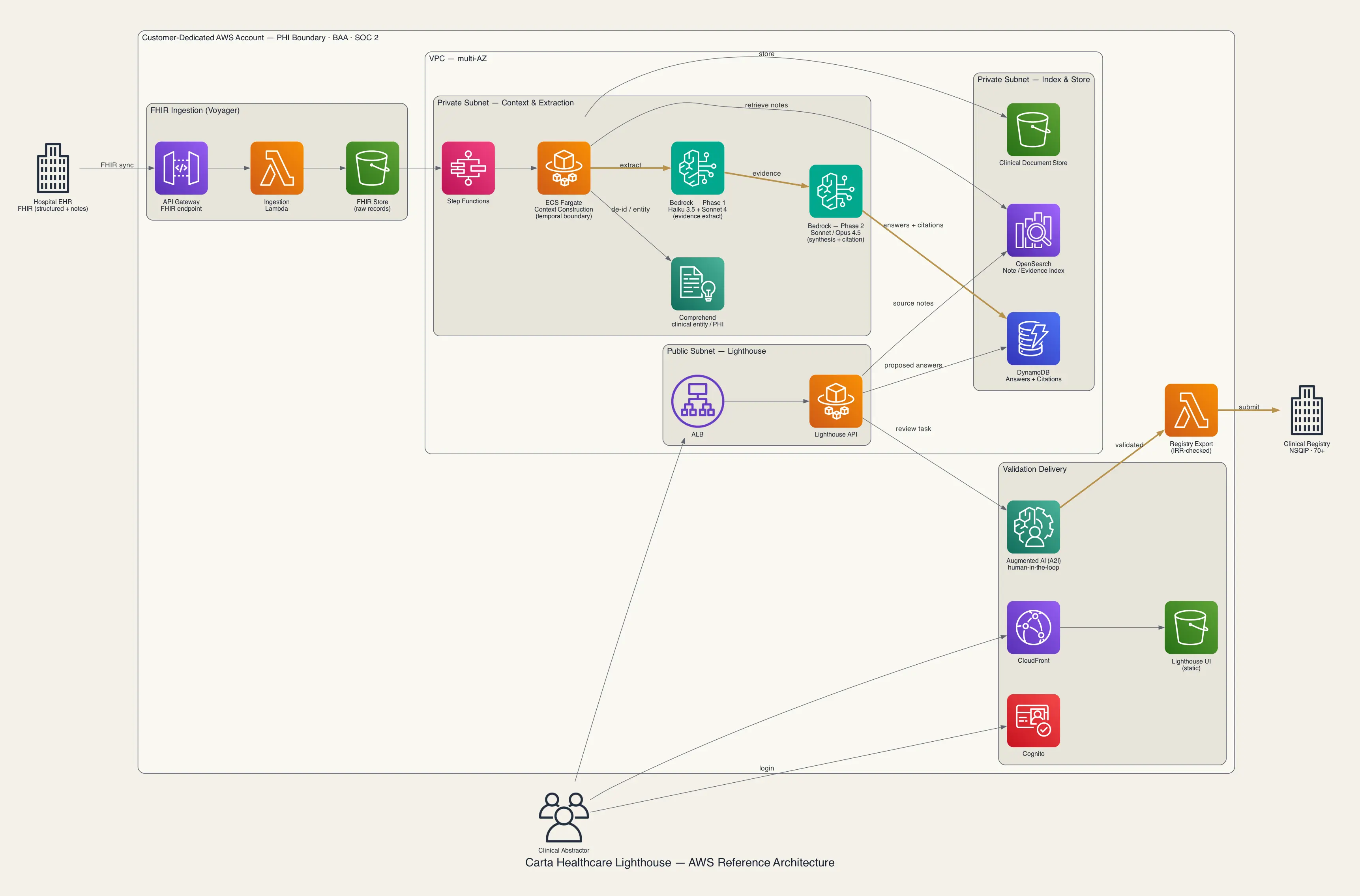
- FHIR ingestion - API Gateway, Lambda, S3: Receives FHIR resources from the EHR and stores raw medical records, matching the Voyager ingestion role.
- Orchestration - AWS Step Functions, ECS Fargate: Controls staged workflows and runs workers for registry-question-specific context construction, including patient temporal boundary assembly.
- Clinical entity / PHI - Amazon Comprehend: Extracts clinical entities and detects or masks sensitive information. In healthcare use cases, this corresponds to Comprehend Medical.
- Phase 1 extraction - Amazon Bedrock (Claude Haiku 3.5 + Sonnet 4): Broadly extracts evidence from the medical record.
- Phase 2 synthesis - Amazon Bedrock (Claude Sonnet / Opus 4.5): Synthesizes and scores evidence to generate suggested answers and citations.
- Index & Retrieval - Amazon OpenSearch Service: Maintains searchable indexes for clinical notes and evidence spans.
- Answers & Citations - Amazon DynamoDB: Stores suggested answers, confidence, and medical-record citations.
- Clinical document store - Amazon S3: Stores unstructured clinical documents.
- Validation (Human-in-the-loop) - CloudFront + S3, ALB + ECS Fargate, Amazon Cognito, Augmented AI (A2I): Provides abstractor validation UI/API, authentication, and structured human review workflows.
- Registry export - AWS Lambda: Exports verified data that passes IRR checks into clinical registry formats such as NSQIP.
- Security & Audit - IAM, KMS, CloudTrail, CloudWatch: Applies permissions, encryption, audit, and monitoring across the full path. Data is protected with AES-256 at rest and TLS 1.2+ in transit.
The bronze path highlights the core path where cost, latency, and accuracy concentrate: two-stage Bedrock inference and the validated data flow into registry submission. Cross-cutting security and audit services are not drawn in the diagram and are summarized above. The essential boundary in this case is the customer-dedicated AWS account. AWS is an example implementation, and the same pattern can move to another PHI-safe environment.
3. Workflow
Ingest medical records
Structured patient data and clinical notes enter together from the EHR through FHIR.
Construct context
For each registry question, the system aligns patient temporal boundaries and collects the required medical-record sections.
Run two-stage AI extraction
Phase 1 extracts evidence, and Phase 2 generates suggested answers and medical-record citations.
Expert validation
The abstractor reviews citations in the Lighthouse UI and approves or corrects the suggested value.
IRR check and submission
Verified data is submitted to clinical registries after IRR checks, and correction history feeds back into prompt improvement.
In this workflow, AI is not the final decision maker. It operates as an assistive operating layer that finds and presents evidence. The abstractor's role shifts from "manual data hunter" to "high-value validator." Every value submitted to a registry is reviewed and approved by a human.
4. Build and Operating Cost
Carta Healthcare has not disclosed its internal operating unit cost. The cost structure and savings pattern can be summarized as follows.
- Model API cost: The two-stage routing pattern itself appears to be a token-cost optimization design. Lower-cost models such as Haiku extract evidence broadly, while higher-cost models such as Sonnet or Opus are reserved for focused synthesis. Medical records are long, so input tokens per case can be large, making this separation economically important.
- Data processing and storage cost: FHIR ingestion, clinical document storage, evidence retrieval indexes, and context construction workers add infrastructure cost.
- Security and compliance cost: Because the workflow handles PHI, dedicated AWS accounts per customer, BAAs, SOC 2 controls, encryption at rest and in transit, audit logs, and retention policies are part of the required cost base.
- Validation operations cost: Clinical abstractor time remains a major cost component. The benefit is that abstractors focus on validating suggested answers and evidence instead of searching through records from scratch.
The reported savings include more than 50% reduction in abstraction cost for customers, 3,667-6,050 labor hours saved per health system annually, and more than 11,000 manual hours reduced per registry program.
5. Business Benefits
Faster Processing Time
Based on the public case study, processing time fell by up to 66%. Routine cases dropped from 30 minutes to 15-22 minutes, and complex cases dropped from five to six hours to 90 minutes. Abstractors spend less time on repetitive search and more time on judgment.
Maintained Data Quality
The system increased speed while maintaining 98-99% IRR across more than 22,000 surgical cases and 14 hospitals. The design is supported by always showing evidence citations with suggested answers.
Operational Scalability
Health systems can avoid scaling abstraction headcount linearly with case volume. This creates significant operational leverage in clinical data management, where registry fields are numerous and cases accumulate continuously.
Workforce Role Shift
The clinician's role shifts from "manual data hunter" to "high-value validator." Skilled experts are used for judgment and verification rather than repetitive data entry. The public case links this shift to 100% customer retention and 90% expansion in usage scope.
6. Implications for Regulated Industries and B2B Companies
This case extends beyond clinical data to regulated document work where evidence and audit trails are mandatory. Similar patterns appear in tasks such as:
- Extracting regulatory submission fields from manufacturing quality records, such as defect causes and corrective actions
- Extracting regulatory fields from clinical trial documents in medical devices and pharmaceuticals
- Verifying insurance claims with medical-record evidence
- Extracting regulatory reporting fields from safety and environmental reports
- Extracting compliance fields from contracts and certification documents under audit
The common pattern is that documents are long, formats vary, important values are hidden in small sections, and incorrect values create regulatory risk. The success requirements are therefore similar. AI should not freely summarize or decide every document. Teams need an operating workflow that connects field definitions, source citations, expert validation, quality measurement such as IRR, and system submission. When PHI or confidential data is involved, isolated deployment and assurance that data is not used for model training should be reviewed before model choice.
7. Adoption Checklist
- Are the fields to extract, such as registry questions, clearly defined?
- Does each field preserve the source evidence, such as a medical-record citation or page reference?
- Are temporal boundaries assembled accurately at runtime for fields where timing matters?
- Is data blocked from registry or downstream-system submission until an expert validates it?
- Is data quality continuously measured with a metric such as IRR?
- Is PHI or sensitive data processed only inside an isolated environment, with assurance that it is not used for model training?
- Are low-cost and high-cost models separated by stage to control token cost?
- Does correction history from validation feed back into prompt and evaluation improvement?
8. References
- Carta Healthcare customer story (Claude)
- Carta Healthcare clinical abstractor (Claude blog)
- Claude for Healthcare powers Carta Healthcare's hybrid intelligence (Carta PR)
- PR Newswire press release
- Carta AI Platform