
OpenAI의 finance team은 계약서 검토 업무에서 반복적으로 발생하던 병목을 줄이기 위해 Contract Data Agent / DocuGPT를 운영 사례로 공개했다. 이 시스템은 PDF, 스캔본, 휴대폰 사진, 손글씨 수정본처럼 형태가 제각각인 계약 문서를 읽고, 청구 조건, 갱신 조건, ASC 606 분류, 비표준 조항 같은 핵심 필드를 구조화한다.
핵심은 단순한 문서 요약이 아니다. 계약서 안의 근거 페이지와 조항을 함께 제시하고, finance reviewer가 승인하거나 수정한 결과를 데이터웨어하우스에 적재해 이후 검색과 분석이 가능하게 만든다. 공개 사례에 따르면 리뷰 시간은 절반으로 줄었고, 수천 건의 계약을 headcount에 선형으로 의존하지 않고 처리할 수 있게 됐다.
1. 사용된 AI 기술
- 문서 인입 및 정규화: PDF, scan, phone photo, handwritten edit을 OCR과 text extraction으로 표준 텍스트 형태로 변환한다.
- 계약 메타데이터 생성: 계약 ID, 고객명, amendment 여부, clause type, page reference를 붙여 검색 가능한 단위로 나눈다.
- Clause-specific retrieval: billing, renewal, termination, discount, non-standard terms, ASC 606 관련 section을 조항별로 검색한다.
- Structured extraction: 모델이 필드 값, confidence, reasoning, page citation을 함께 생성한다.
- Human-in-the-loop review: finance reviewer가 원문 citation을 확인하며 승인, 수정, 거절한다.
- Warehouse sync: 승인된 필드를 finance warehouse와 BI에서 query 가능한 데이터로 동기화한다.
- Eval feedback loop: reviewer correction을 평가셋과 prompt 개선에 다시 사용한다.
2. 구현 가능한 시스템 아키텍처
아래 구조는 공개된 사례와 일반적인 엔터프라이즈 계약 관리 환경을 바탕으로 정리한 구현안이다. CLM, e-signature, CRM, S3 같은 외부 연동은 실제 구현 시 필요한 구성으로 볼 수 있으나, 원문에서 모든 세부 연동이 명시된 것은 아니다.
계약 파일 인입
PDF, scan, phone photo, handwritten edits처럼 형식이 다른 계약 파일이 들어온다.
OCR과 문서 정규화
OCR과 text extraction으로 계약 문서를 표준 텍스트 형태로 바꾼다.
Chunking과 메타데이터 생성
계약 ID, 고객, 조항, 페이지 기준으로 검색 가능한 단위를 만든다.
조항별 검색과 구조화 추출
billing, renewal, ASC 606, non-standard terms 관련 조항을 찾아 필드 값과 근거를 생성한다.
Finance review와 warehouse sync
재무 담당자가 승인한 값만 warehouse와 BI에서 query 가능한 계약 데이터로 적재한다.
실제 서비스로 구축한다면 — AWS 레퍼런스 아키텍처
위 논리 흐름을 실제 AWS 위에 올리면 아래처럼 구성할 수 있다. 인입·정규화·추출·리뷰·적재 각 단계를 관리형 서비스로 매핑하고, 처리·저장 계층은 VPC(multi-AZ) 안에 둔다.
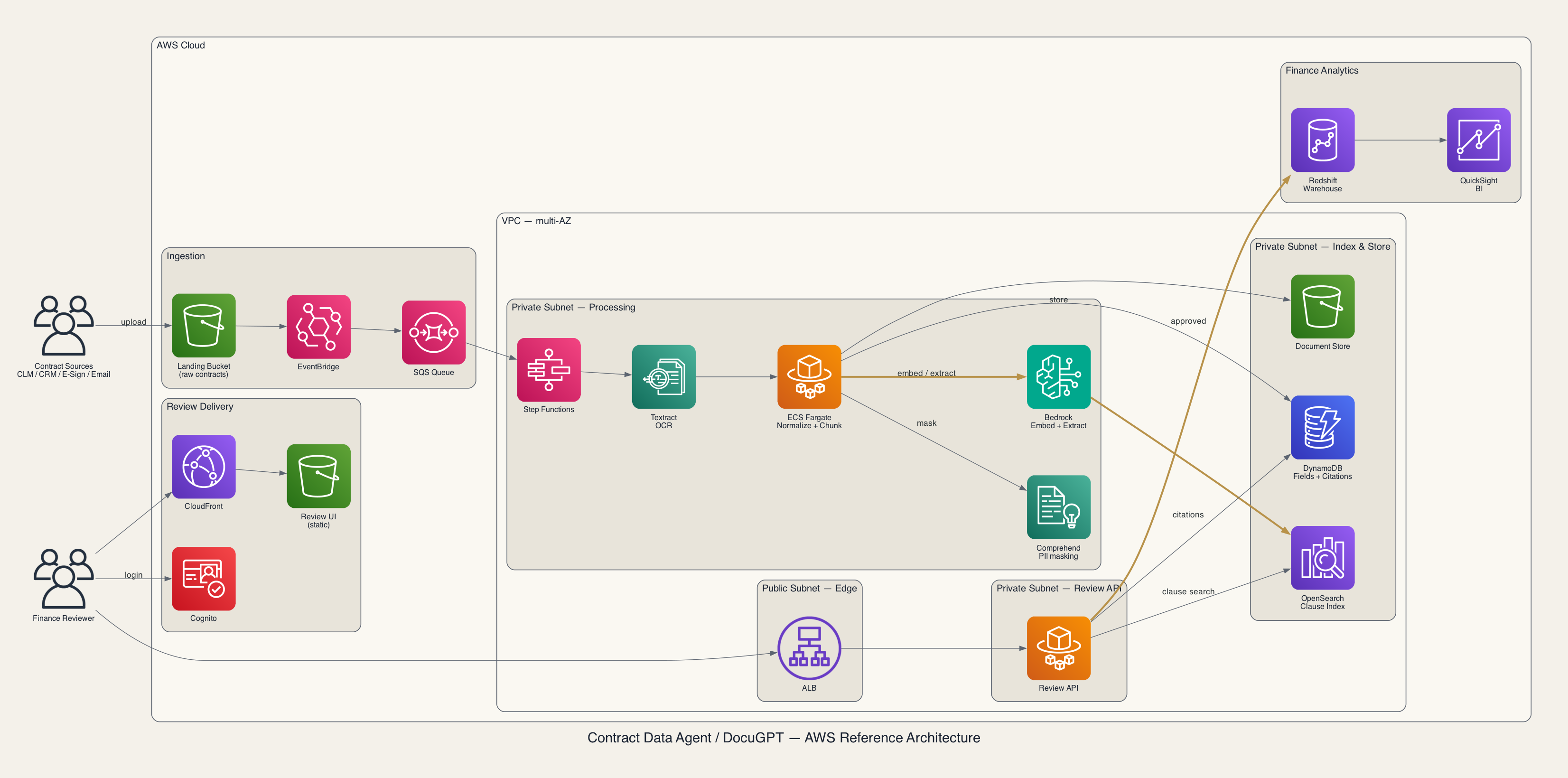
- Contract intake — S3 Landing Bucket · EventBridge · SQS: 외부 SaaS·이메일 첨부의 원본 계약을 적재하고 이벤트로 파이프라인을 기동한다.
- Document normalization — Amazon Textract: 스캔본·사진·손글씨 수정본을 OCR로 정규화한다.
- Orchestration — AWS Step Functions · ECS Fargate: 단계별 워크플로 제어와 정규화·청킹 워커를 실행한다.
- Embedding & Extraction — Amazon Bedrock: 임베딩 생성과 필드값·reasoning·confidence·citation 구조화 추출.
- Indexing & Retrieval — Amazon OpenSearch Service: billing·renewal·ASC 606 등 조항별 검색 인덱스.
- Extracted data — Amazon DynamoDB: 추출 값·confidence·page citation 저장.
- Review (Human-in-the-loop) — CloudFront + S3 · public ALB · private ECS Fargate · Amazon Cognito: reviewer 승인 UI·API와 인증.
- Warehouse & BI — Amazon Redshift · Amazon QuickSight: 승인 데이터 적재와 분석·대시보드.
- PII masking — Amazon Comprehend: 가격·고객명 등 민감정보 탐지·마스킹.
- Security & Audit — IAM · KMS · CloudTrail · CloudWatch: 전 구간에 횡단 적용(권한·암호화·감사·모니터링).
bronze로 강조한 경로는 비용·지연·리스크가 집중되는 핵심 경로(Bedrock 추론, 승인 데이터 적재)다. 보안·감사 요소는 전 구간에 횡단 적용되므로 그림에서는 생략하고 위 목록으로 정리했다. AWS는 예시 구현이며, 동일 패턴을 GCP·Azure나 온프레미스로 옮길 수도 있다.
프로덕션 설계에서 보완할 점
위 구성은 실제 구축 가능한 레퍼런스지만, 프로덕션 설계 문서로 사용하려면 운영 경계를 더 명확히 해야 한다.
- Review API는 private subnet에 둔다: CloudFront는 정적 review UI를 제공하고 Cognito가 reviewer 인증을 담당한다. 외부에 노출되는 구성요소는 public ALB까지로 제한한다. ALB는 TLS, WAF, 보안 그룹 정책을 적용한 뒤 private subnet의 ECS Fargate Review API로만 트래픽을 전달한다. Review API task에는 public IP를 부여하지 않고, 운영 접근은 SSM Session Manager나 배포 파이프라인으로 제한한다.
- Bedrock 결과는 worker가 검증한 뒤 OpenSearch에 기록한다: Bedrock 자체가 OpenSearch에 직접 쓰는 구조가 아니다. Step Functions가 ECS Fargate worker를 실행하고, worker가 Bedrock embedding/extraction 호출 결과를 받아 JSON schema, confidence threshold, page citation 존재 여부를 검증한다. 검증된 chunk, vector, clause metadata만 OpenSearch에 upsert하고, 원문·추출 결과·review 상태는 S3와 DynamoDB에 저장한다. Bedrock Knowledge Bases를 쓰는 경우에도 sync job과 승인 데이터 적재 경로를 별도로 설계해야 한다.
- PII와 언어 한계를 별도 정책으로 둔다: Amazon Comprehend의 PII 탐지는 주로 영어·스페인어 텍스트에 적합하므로, 한국어 계약서나 다국어 계약서에서는 충분하지 않을 수 있다. 가격 조건, 고객명, 계좌, 주소, 담당자 정보는 regex, custom NER, Bedrock Guardrails, 사내 용어 사전, reviewer 확인을 조합해 마스킹한다. OCR 품질도 스캔 해상도, 손글씨, 표 구조, 언어에 따라 달라지므로 실제 계약 샘플로 Textract와 extraction 정확도를 먼저 평가해야 한다.
- 운영 재처리·감사·권한 모델을 설계한다: SQS DLQ, Step Functions retry/catch, idempotency key, 재처리 버튼을 둬 같은 계약이 중복 적재되지 않게 한다. 모든 추출 값은 contract ID, document version, prompt version, model version, source page, reviewer ID, approval timestamp를 audit trail로 남긴다. IAM은 ingestion worker, extraction worker, review API, warehouse loader별 least privilege role로 분리하고, KMS key policy, CloudTrail data events, CloudWatch metrics/alarms, VPC endpoints를 함께 정의한다.
3. 업무 흐름
계약서 인입
계약서가 시스템으로 들어온다.
OCR 및 텍스트 정규화
스캔본, 사진, PDF에서 텍스트를 추출하고 문서 형태를 맞춘다.
조항별 검색과 AI 추출
청구, 갱신, 수익인식, 비표준 조항을 찾아 구조화 필드로 추출한다.
담당자 검토와 승인
재무 담당자가 citation을 확인하고 승인하거나 수정한다.
데이터 적재와 개선 환류
승인 데이터는 warehouse와 BI에 적재되고, 수정 이력은 평가셋과 prompt 개선으로 돌아간다.
이 흐름에서 AI는 최종 의사결정자가 아니라 계약 데이터 추출과 근거 제시를 자동화하는 보조 운영 레이어로 작동한다. 중요한 값은 사람이 확인하고 승인한 뒤에만 재무 시스템으로 들어간다.
4. 구축 및 운영 비용
OpenAI 내부 운영비는 공개되지 않았다. 다만 비슷한 규모의 파일럿을 가정하면 비용 구조는 다음처럼 나눌 수 있다.
- 모델 API 비용: 1,000 contracts/month, 계약당 평균 30~80페이지, OCR 후 계약당 50,000~150,000 input tokens를 2단계로 처리할 경우 월 수백~수천 달러 범위로 추정할 수 있다.
- 문서 처리 비용: OCR, 문서 저장소, 임베딩 인덱스, 검색 인프라 비용이 추가된다.
- 보안 및 감사 비용: 계약 및 재무 데이터는 권한 관리, 감사 로그, retention policy, PII/민감정보 마스킹을 반드시 포함해야 한다.
- 리뷰 운영 비용: finance reviewer time이 총비용에서 큰 비중을 차지할 수 있다. 다만 reviewer가 모든 문서를 처음부터 읽는 대신 예외 조항 판단과 승인에 집중하게 되는 것이 핵심 이익이다.
5. 비즈니스 이익
계약 리뷰 시간 단축
공개 사례 기준으로 리뷰 시간이 절반으로 줄었다. 계약서에서 값을 찾는 반복 작업이 줄고, reviewer는 판단이 필요한 예외 조항에 더 많은 시간을 쓸 수 있다.
수천 건 계약 처리의 확장성 확보
계약량이 늘 때마다 재무 인력을 같은 비율로 늘리는 구조에서 벗어날 수 있다. 이는 빠르게 성장하는 B2B 기업에서 특히 큰 운영 레버리지다.
계약 데이터의 검색 가능성 확보
승인된 계약 필드가 warehouse에 적재되면 billing terms, renewal terms, non-standard terms, ASC 606 classification을 쿼리로 조회할 수 있다. 계약서가 파일 저장소에 묻혀 있는 문서가 아니라 분석 가능한 재무 데이터가 된다.
감사 대응력 강화
추출 값마다 page citation과 reviewer approval trail을 남기면, 내부 감사나 외부 감사에서 “왜 이 값이 이렇게 분류됐는가”를 설명하기 쉬워진다.
6. 제조·B2B 기업에 주는 시사점
이 사례는 재무 계약뿐 아니라 제조·B2B 운영 문서에도 그대로 확장할 수 있다. 예를 들어 다음과 같은 문서는 모두 비슷한 구조를 가진다.
- 고객사별 공급 계약과 납품 조건
- 품질 보증 조건과 penalty clause
- 설비 유지보수 계약
- 구매 계약과 단가 변경 합의서
- 장기 공급 계약의 갱신·해지 조건
- 수출입 문서와 Incoterms 조건
공통점은 문서가 길고, 형식이 제각각이며, 중요한 값은 일부 조항에 숨어 있다는 점이다. 따라서 성공 요건도 같다. AI가 모든 문서를 자유롭게 요약하게 만드는 것이 아니라, 업무상 필요한 필드 정의, 원문 근거, reviewer 승인, 데이터웨어하우스 적재까지 이어지는 운영 흐름을 설계해야 한다.
7. 도입 체크리스트
- 추출해야 할 계약 필드가 명확한가?
- 각 필드의 원문 근거 페이지를 반드시 남기는가?
- reviewer가 승인하기 전에는 재무 시스템에 반영되지 않는가?
- reviewer correction이 eval set으로 축적되는가?
- 계약 문서 접근 권한과 감사 로그가 유지되는가?
- PII, 가격 조건, 고객명, 결제 조건 같은 민감정보 마스킹 정책이 있는가?
- warehouse에 적재된 필드가 BI와 revenue workflow에서 실제로 쓰이는가?
8. 참고 레퍼런스
- Turning contracts into searchable data at OpenAI
- OpenAI API pricing
- OpenAI File Search guide
- OpenAI Function Calling guide