
Carta Healthcare는 병원이 임상 레지스트리(NSQIP 등 70개 이상)에 제출하는 데이터를 만들기 위해 반복하던 임상 데이터 추상화(clinical data abstraction) 작업을 줄이기 위해 Lighthouse를 운영 사례로 공개했다. 임상 데이터 추상화란 환자 의무기록을 사람이 일일이 읽고 레지스트리 항목에 맞는 값을 찾아 옮겨 적는 작업으로, 한 케이스에 길게는 5~6시간이 걸리는 고숙련 수작업이다. Lighthouse는 EHR의 정형 데이터와 비정형 임상 노트를 함께 읽고, 레지스트리 질문마다 제안 답안과 그 근거가 된 의무기록 인용을 함께 제시한다.
핵심은 추출 자동화 그 자체가 아니라 역할의 재배치다. 임상 abstractor(200명 이상의 전문가)는 값을 처음부터 찾아 헤매는 대신, AI가 제안한 답안과 근거 인용을 검증한다. AI는 판단을 대체하지 않고 보조한다. 공개 사례에 따르면 처리 시간은 최대 66% 줄었고, 데이터 품질은 IRR(검토자 간 일치도) 98~99%를 유지했다.
1. 사용된 AI 기술
- FHIR 네이티브 데이터 인입: EHR에서 Patient·Encounter·Observation·DocumentReference·Procedure 같은 FHIR 리소스를 연동해, 정형 데이터와 비정형 임상 노트를 동시에 인제스트한다.
- 런타임 context construction: 가장 어려운 엔지니어링 난제는 "완벽한 프롬프트"가 아니라 컨텍스트 조립이다. 레지스트리 질문마다 환자별 시점 경계(예: 시술 시작 시각 기준 pre-procedure 측정값)를 런타임에 동적으로 구성한다.
- 2단계 LLM 라우팅: Phase 1에서 Claude Haiku 3.5와 Sonnet 4가 의무기록에서 근거를 광범위하게 추출하고, Phase 2에서 Claude Sonnet(2026년 1월부터 Opus 4.5 추가)이 근거를 합성·스코어링·랭킹해 제안 답안을 만든다.
- 직접 인용(citation) 기반 근거: 제안 답안마다 의무기록 원문 인용을 함께 생성해, abstractor가 "찾는" 게 아니라 "검증"하게 만든다. temporal reasoning과 hallucination 저감 레이어가 함께 동작한다.
- Human-in-the-loop 검증: 모든 데이터 포인트는 임상 abstractor가 Lighthouse UI에서 근거를 보며 검증한 뒤에만 레지스트리로 나간다.
- 빠른 QA 루프: 임상가가 코드 수정 없이 프롬프트만 조정해 당일 프로덕션에서 테스트할 수 있어, 추출 품질 개선 사이클이 빠르게 회전한다.
- PHI 격리 배포: Amazon Bedrock 경유로 Claude를 호출하고, 고객별 전용 AWS 계정 안에서만 처리한다. 선택 이유는 PHI 프라이버시 보장과 고객 데이터 미학습이다.
2. 구현 가능한 시스템 아키텍처
아래 구조는 공개된 사례와 일반적인 임상 데이터 관리 환경을 바탕으로 정리한 구현안이다. FHIR 연동, 전용 AWS 계정, 레지스트리 제출 같은 구성은 사례의 핵심 설계로 명시돼 있으나, 모든 세부 서비스 연동이 원문에 일일이 명시된 것은 아니다.
EHR에서 FHIR 인입
병원 EHR에서 FHIR 연동으로 환자 의무기록(정형 + 비정형 노트)을 인제스트한다.
전용 AWS 계정으로 격리
고객별 전용 AWS 계정(BAA·SOC 2·암호화) 안에서만 PHI를 처리한다.
레지스트리 질문별 컨텍스트 조립
질문마다 환자 시점 경계를 런타임에 구성해 필요한 의무기록 구간만 모은다.
2단계 추출과 근거 생성
Phase 1이 근거를 추출하고, Phase 2가 합성·스코어링해 제안 답안과 인용을 만든다.
Abstractor 검증과 레지스트리 제출
임상 전문가가 근거를 보며 검증한 값만 IRR 확인 후 임상 레지스트리로 제출한다.
실제 서비스로 구축한다면 — AWS 레퍼런스 아키텍처
위 논리 흐름을 실제 AWS 위에 올리면 아래처럼 구성할 수 있다. 인입·컨텍스트·추출·검증·제출 각 단계를 관리형 서비스로 매핑하고, 전체 처리를 고객 전용 AWS 계정(PHI 경계) 안에 둔다.
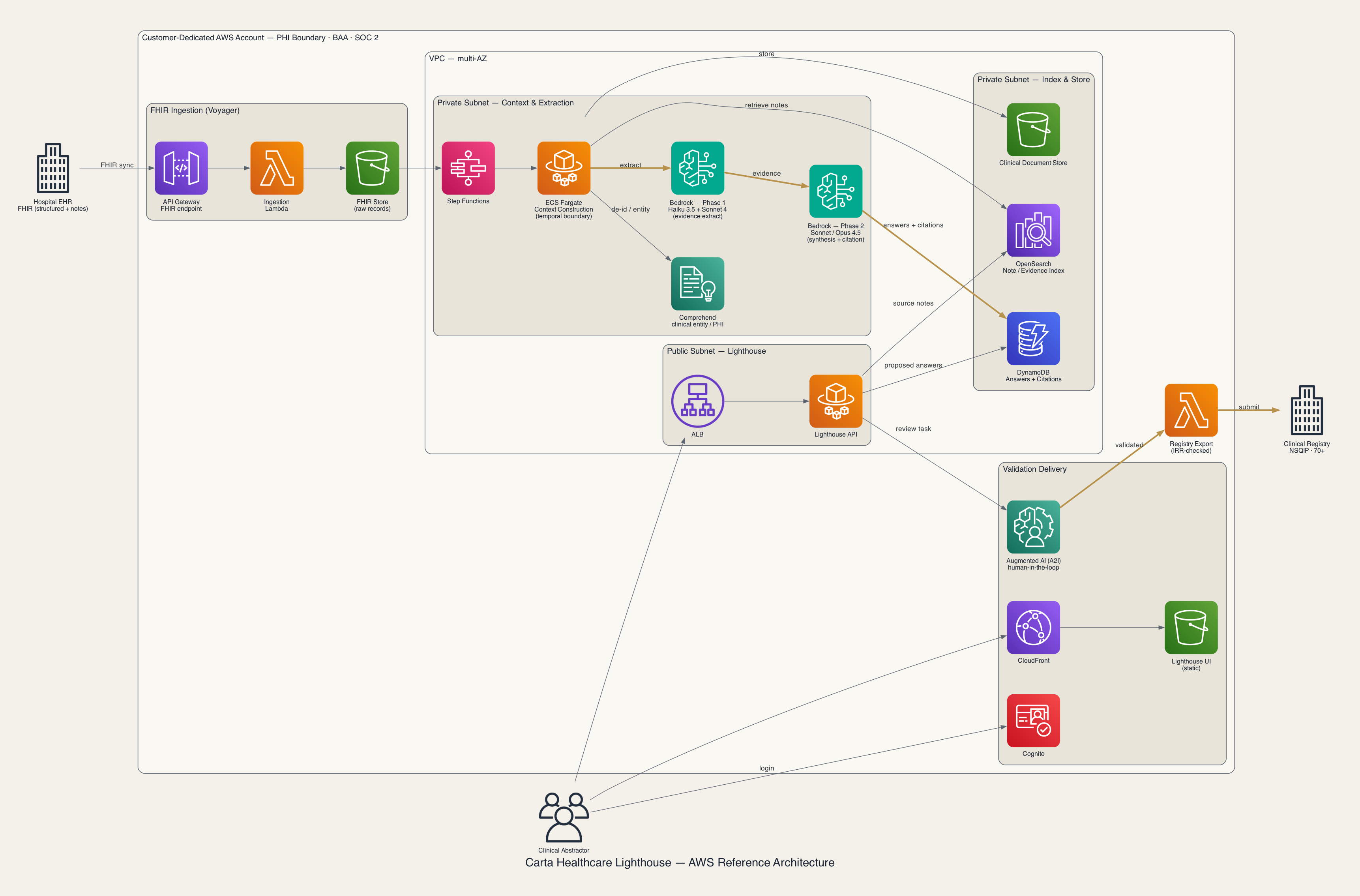
- FHIR ingestion — API Gateway · Lambda · S3: EHR의 FHIR 리소스를 받아 원본 의무기록을 적재한다(Voyager 인제스천 역할).
- Orchestration — AWS Step Functions · ECS Fargate: 단계별 워크플로 제어와 레지스트리 질문별 context construction(환자 시점 경계 조립) 워커를 실행한다.
- Clinical entity / PHI — Amazon Comprehend: 임상 엔티티 추출과 민감정보 탐지·마스킹(헬스케어 도메인에서는 Comprehend Medical에 해당).
- Phase 1 추출 — Amazon Bedrock(Claude Haiku 3.5 + Sonnet 4): 의무기록에서 근거를 광범위하게 추출한다.
- Phase 2 합성 — Amazon Bedrock(Claude Sonnet / Opus 4.5): 근거를 합성·스코어링해 제안 답안과 citation을 생성한다.
- Index & Retrieval — Amazon OpenSearch Service: 임상 노트·근거 구간을 검색하는 인덱스.
- Answers & Citations — Amazon DynamoDB: 제안 답안·confidence·의무기록 인용 저장.
- Clinical document store — Amazon S3: 비정형 임상 문서 저장소.
- Validation (Human-in-the-loop) — CloudFront + S3 · ALB + ECS Fargate · Amazon Cognito · Augmented AI(A2I): abstractor 검증 UI·API와 인증, 구조화된 휴먼 리뷰 워크플로.
- Registry export — AWS Lambda: IRR 확인을 통과한 검증 데이터를 임상 레지스트리(NSQIP 등) 포맷으로 내보낸다.
- Security & Audit — IAM · KMS · CloudTrail · CloudWatch: 전 구간에 횡단 적용(권한·암호화·감사·모니터링). 데이터는 AES-256(저장)/TLS 1.2+(전송)로 보호한다.
bronze로 강조한 경로는 비용·지연·정확도가 집중되는 핵심 경로(2단계 Bedrock 추론, 검증 데이터의 레지스트리 제출)다. 보안·감사 요소는 전 구간에 횡단 적용되므로 그림에서는 생략하고 위 목록으로 정리했다. 이 사례의 본질적 경계는 고객 전용 AWS 계정이며, AWS는 예시 구현이다. 동일 패턴을 다른 PHI-safe 환경으로 옮길 수도 있다.
3. 업무 흐름
의무기록 인입
EHR에서 FHIR로 환자의 정형 데이터와 임상 노트가 함께 들어온다.
컨텍스트 조립
레지스트리 질문별로 환자 시점 경계를 맞춰 필요한 의무기록 구간을 모은다.
2단계 AI 추출
Phase 1이 근거를 추출하고, Phase 2가 제안 답안과 의무기록 인용을 생성한다.
전문가 검증
abstractor가 Lighthouse UI에서 근거 인용을 확인하며 승인하거나 수정한다.
IRR 확인과 제출
검증된 데이터는 IRR(98~99%) 확인 후 임상 레지스트리로 제출되고, 수정 이력은 프롬프트 개선으로 돌아간다.
이 흐름에서 AI는 최종 의사결정자가 아니라 근거를 찾아 제시하는 보조 운영 레이어로 작동한다. abstractor의 역할은 "값을 직접 찾는 사람(manual data hunter)"에서 "근거를 검증하는 사람(high-value validator)"으로 바뀐다. 레지스트리에 들어가는 모든 값은 사람이 확인하고 승인한 뒤에만 제출된다.
4. 구축 및 운영 비용
Carta Healthcare 내부 운영비 단가는 공개되지 않았다. 다만 비용 구조와 절감 효과는 다음처럼 정리할 수 있다.
- 모델 API 비용: 2단계 라우팅 자체가 토큰 비용 최적화 설계로 해석된다. 저비용 모델(Haiku)로 광범위하게 근거를 추출하고, 고비용 모델(Sonnet/Opus)은 핵심 합성에만 쓰는 구조다. 의무기록은 길어 케이스당 입력 토큰이 크므로, 이 분리가 비용에 직접적인 영향을 준다.
- 데이터 처리·저장 비용: FHIR 인입, 임상 문서 저장소, 근거 검색 인덱스, 컨텍스트 조립 워커 비용이 추가된다.
- 보안 및 컴플라이언스 비용: PHI를 다루므로 고객별 전용 AWS 계정, BAA, SOC 2, 저장·전송 암호화, 감사 로그, retention policy가 필수 비용에 포함된다.
- 검증 운영 비용: 임상 abstractor의 시간이 여전히 비용에서 큰 비중을 차지한다. 다만 처음부터 의무기록을 뒤지는 대신 제안 답안과 근거를 검증하는 데 집중하게 되는 것이 핵심 이익이다.
절감 효과(검증 기준)는 고객 측 abstraction 비용 50% 이상 절감, health system당 연 3,667~6,050시간 인건시 절감, 레지스트리 프로그램당 11,000시간 이상의 수작업 감축으로 보고됐다.
5. 비즈니스 이익
처리 시간 단축
공개 사례 기준으로 처리 시간이 최대 66% 줄었다. 루틴 케이스는 30분에서 15~22분으로, 복잡 케이스는 5~6시간에서 90분으로 단축됐다. abstractor가 값을 찾는 반복 작업이 줄고, 판단이 필요한 부분에 시간을 쓸 수 있다.
데이터 품질 유지
자동화로 속도를 올리면서도 IRR(검토자 간 일치도)을 98~99%로 유지했다(연 22,000건 이상의 외과 케이스, 14개 병원 기준). 근거 인용을 항상 함께 제시하는 설계가 품질을 떠받친다.
확장성 확보
케이스가 늘 때마다 추상화 인력을 같은 비율로 늘리는 구조에서 벗어날 수 있다. 레지스트리 항목이 많고 케이스가 꾸준히 쌓이는 임상 데이터 관리에서 큰 운영 레버리지다.
인력의 역할 전환
임상가의 역할이 "manual data hunter → high-value validator"로 전환된다. 고숙련 인력을 단순 데이터 입력이 아니라 판단과 검증에 배치하게 된다. 고객 유지율 100%, 사용 범위 90% 확대로 이어졌다.
6. 규제 산업·B2B 기업에 주는 시사점
이 사례는 임상 데이터뿐 아니라 근거와 감사 추적이 필수인 규제 산업 문서 작업에 그대로 확장된다. 예를 들어 다음과 같은 작업은 모두 비슷한 구조를 가진다.
- 제조 품질 기록에서 규제 제출용 항목(예: 불량 원인, 시정 조치) 추출
- 의료기기·제약의 임상시험 문서에서 규제 항목 추출
- 보험 청구 심사에서 의무기록 기반 항목 검증
- 안전·환경 보고서에서 규제 보고 항목 추출
- 감사 대상 계약·인증 문서에서 준수 항목 추출
공통점은 문서가 길고, 형식이 제각각이며, 중요한 값이 일부 구간에 숨어 있고, 틀리면 규제 리스크가 크다는 점이다. 따라서 성공 요건도 같다. AI가 모든 문서를 자유롭게 요약·결정하게 만드는 것이 아니라, 항목 정의, 원문 근거 인용, 전문가 검증, 품질 측정(IRR류), 시스템 제출까지 이어지는 운영 흐름을 설계해야 한다. 특히 PHI·기밀을 다룰 때는 전용 격리 환경과 데이터 미학습 보장이 모델 선택보다 먼저 검토돼야 한다.
7. 도입 체크리스트
- 추출해야 할 항목(레지스트리 질문 등)이 명확히 정의돼 있는가?
- 각 항목의 원문 근거(의무기록 인용·페이지)를 반드시 함께 남기는가?
- 시점 경계(temporal boundary)가 중요한 항목을 런타임에 정확히 조립하는가?
- 전문가가 검증하기 전에는 레지스트리·하위 시스템에 반영되지 않는가?
- 데이터 품질을 IRR 같은 지표로 지속 측정하는가?
- PHI·민감정보가 전용 격리 환경에서만 처리되고, 모델 학습에 쓰이지 않음이 보장되는가?
- 저비용·고비용 모델을 단계별로 분리해 토큰 비용을 통제하는가?
- 검증 과정에서 나온 수정 이력이 프롬프트·평가 개선으로 환류되는가?
8. 참고 레퍼런스
- Carta Healthcare customer story (Claude)
- Carta Healthcare clinical abstractor (Claude blog)
- Claude for Healthcare powers Carta Healthcare's hybrid intelligence (Carta PR)
- PR Newswire 보도자료
- Carta AI Platform